? ? ? ?本講座中,何暉光教授首先介紹課題組在醫學影像分析方面的幾個工作,進而介紹視覺信息編解碼的工作。
? ? ? ?視覺信息編解碼是通過計算方法建立從視覺系統與外界視覺刺激信息之間的映射模型,探索大腦視覺信息處理的過程和機理,其研究不僅有助于探索視覺的加工機制,而且可促進計算機視覺的類腦研究。
? ? ? ?2020年6月19日中國科學院自動化研究所何暉光研究員受南方科技大學生物醫學工程系劉泉影助理教授邀請在生物醫學工程系生物醫學講堂進行了題為《從神經影像計算與分析到視覺信息編解碼》的講座。本文為該講座的總結推文。
一、研究背景
? ? ? ?視覺信息編解碼涉及到的問題非常廣泛,其中有很多重要問題長期得不到解決。視覺系統是人類感知外部世界的最主要途徑,大腦視覺皮層基于視網膜感受器采集到的信息,在我們腦中準確地重建出外界環境的樣子。一方面視覺加工過程最快約在200ms以內完成,是一個瞬間、動態的過程。另一方面,外部視覺刺激是多種多樣、雜亂無章的,人類的視覺系統卻能穩定地識別和理解這些視覺輸入。這些問題都需要我們更深入的了解大腦中視覺信息的編解碼問題來解決。
? ? ? ?從視覺皮層的編碼特征上來看,視覺信號從V1-V2-V4-PIT-IT 信息的逐層處理過程中,對應的神經元的感受野越來越大;每層之間感受野增大的系數大體為2.5;高級別的神經元將信息集成在具有較小感受野的多個低級神經元上,編碼更復雜的特征。分別來說,V1區是編碼的邊緣和線條等基本特征;V2區神經元對錯覺輪廓有反應,是色調敏感區;V3區是信息過渡區;V4是色彩感知的主要區域,參與曲率計算、運動方向選擇和背景分離;IT區是物體表達和識別區(圖1、圖2)。從近些年來深度學習和機器視覺的發展可以看出,深度卷積網絡也與視覺皮層的編碼特征呈現出了類似的形態(圖3)。
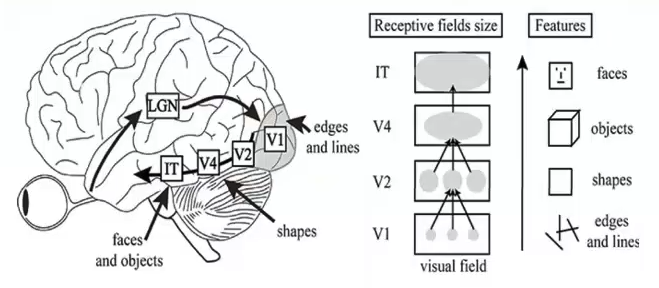
圖1 視覺信號分層編碼
?
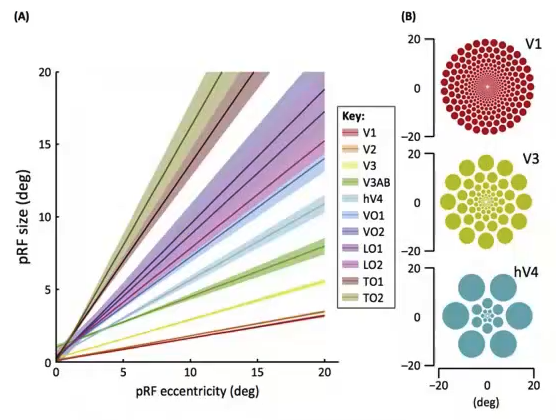
圖2 不同區域神經元編碼不同特征
?
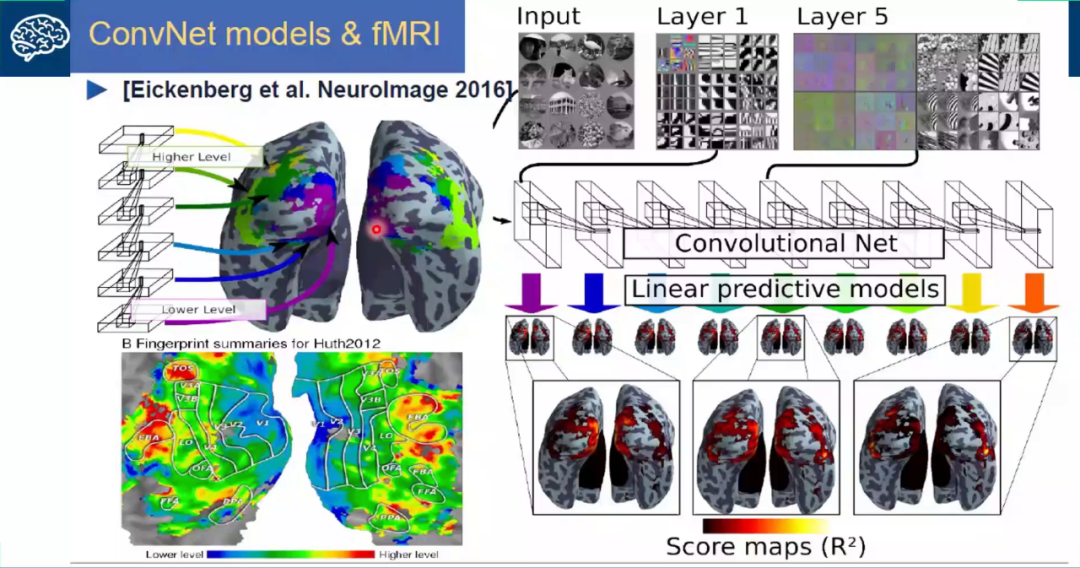
圖3 深度卷積網絡與大腦分層解碼結構
二、視覺信息編解碼
? ? ? ?視覺編解碼是建立視覺刺激和大腦反應之間的關系,編碼是將視覺信號轉化為大腦反應,解碼為將大腦反應轉化為視覺信號。何老師認為編碼問題在這個過程中有更重要的地位,反映了神經信號加工的機理,更加具有科學價值。在神經信號編解碼過程中,往往不會直接使圖像對神經信號進行映射,而是先從圖像通過非線性變換提取特征,再使用線性編解碼器將圖像特征和神經信號特征相互連接(圖4)。這樣做可以降低數據維度,減少計算量和需要的數據量;又能避免編解碼過程成為一個黑盒,具有更好的可解釋性;同時還能一定程度上避免非線性運算造成的過擬合。
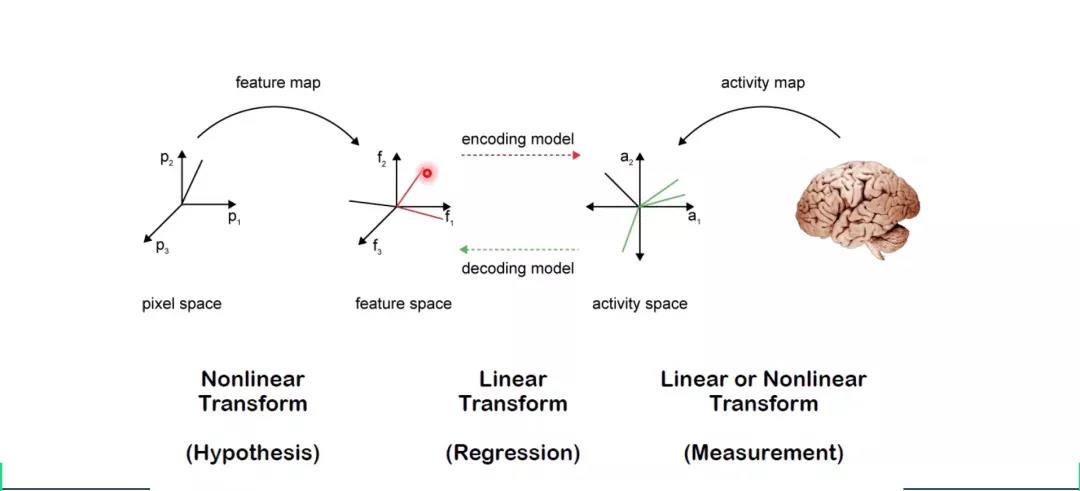
圖4 視覺信息編解碼過程
? ? ? ?在介紹了幾個重要的解碼模型后,何老師提出了目前視覺信息解碼研究中存在的問題。首先,大多數方法只針對分類或辨識任務;其次,重建算法的效果不佳;最后,常用的線性變換手段缺乏生物學基礎。其中一部分原因是由于視覺信息解碼中的(fMRI)數據特點造成的。這些數據具有維度高、樣本量小、噪音嚴重的特點,對我們應用編解碼模型會造成很大的困擾。根據此,何老師提出了《基于視覺信息編解碼的深度學習類腦機制研究》項目,該項目有兩點目標:1)建立人類視覺系統與外部視覺刺激信息之間的映射模型,利用深度學習對大腦視覺信號進行編解碼,探索深度學習的類腦機制;2)通過對視覺信息的編解碼,引導深度神經網絡建模。
? ? ? ?比較直接的辦法是將深度神經網絡(例如convolutional auto-encoder 卷積自編碼器)作為圖像和神經信號的特征提取器,再將其特征相互映射(圖4)。這種方法被稱為兩階段法,即特征提取和映射分開進行。同時也可以使用統一訓練的方法,將自編碼器圖像特征提取和與神經信號相互映射兩個步驟合并為一步,進行統一訓練(圖5)。
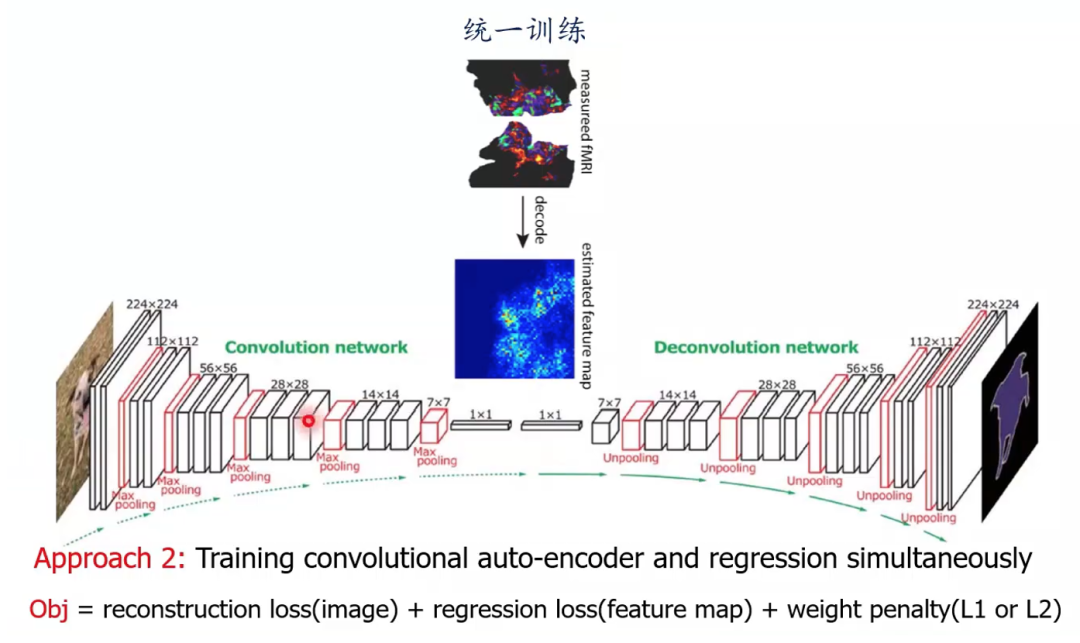
圖5 卷積自編碼器用于圖像與大腦信號特征提取
三、多視圖生成式自編碼模型
? ? ? ?然后何老師介紹了多視圖生成式自編碼模型(Deep generative multi-view model(DGMM)),該研究由何老師課題組博士生杜長德(已畢業)完成。該模型基于這樣一個假設,即視覺圖像和大腦響應是同一客體在不同特征空間中的外在表征。由該假設可得視覺圖像和大腦響應可以由同一隱含變量通過不同的生成模型得到。這樣一來,視覺圖形重建問題就轉變為了多視圖隱含變量模型中缺失視圖的貝葉斯推斷問題。
? ? ? ?所以基于圖像我們采用深度神經網絡(DNNs)建立推理(Inference)網絡和生成(Generative)網絡,這樣一組推理網絡和生成網絡構成了變分自編碼器(VAE)架構,可以模擬大腦視覺信息處理機制(層次化,Bottom-up, Top-down)(圖6,左上到右上)。對于大腦響應,建立稀疏貝葉斯線性模型(圖6,左下到右下),模擬體素感受野和視覺信息的稀疏表達準則。這樣做可以自動降低體素空間維度,避免過擬合;同時可以利用體素間相關性來抑制噪聲,魯棒性更強;最后由于對體素協方差矩陣施加了低秩約束,降低了計算復雜度。
? ? ? ?在訓練好這兩組推理與生成模型后,給定新的視覺圖像輸入,就可以通過Bottom-up的推理網絡得到隱含表征,再通過線性生成模型預測大腦活動,這就是視覺信息編碼通路。反之,給定新的大腦響應,將先驗知識(表征相似性分析)融入到貝葉斯推理中,得到隱含表征,再通過Top-down的生成網絡預測視覺圖像,這就是視覺信息解碼通路。
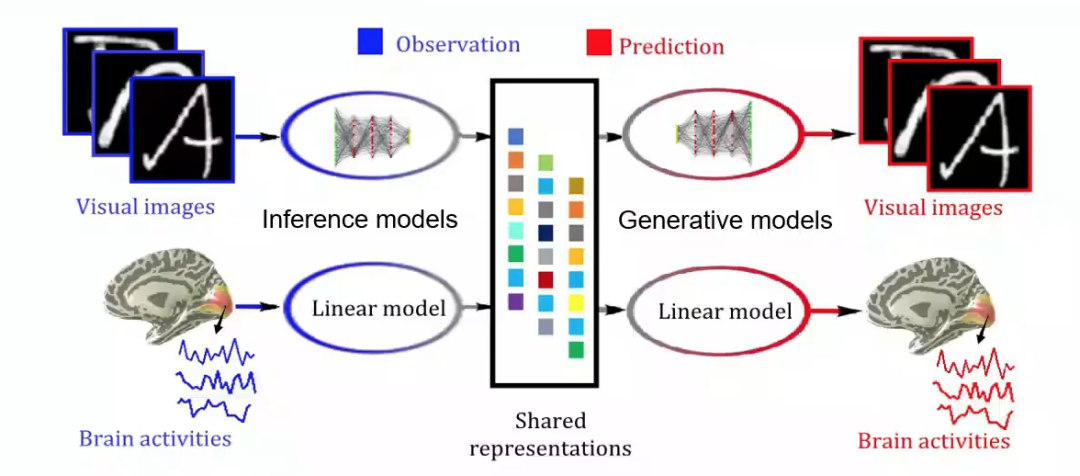
圖6 多視圖生成式自編碼模型結構
? ? ? ?在實際訓練中,我們將圖像和神經信號輸入同一個推斷模型,來保證生成的隱含表征在同一個空間中,再分別進入各自的生成模型中進行重建(圖7)。在測試中,我們通過對輸入的大腦響應與一直大腦響應的相似度矩陣,通過貝葉斯推斷得到對應的隱含表征,再通過生成網絡預測視覺圖像(圖8)。該研究在三個公開數據集中都進行了測試,這些數據集主要記錄了大腦V1和V2的活動。在與多個方法的對比結果中,該模型無論是肉眼觀測的圖像重建效果還是在數值指標上,均有最好的表現(圖9)。在被試差異和模型可解釋性上,該研究也進行了分析。最后,通過對fMRI中體素權重的可視化,該模型展現出了在神經科學研究中的潛力。這項研究得到了MIT Technology Review的高度評價,認為該研究在腦機接口方面做出了一項重要的貢獻。
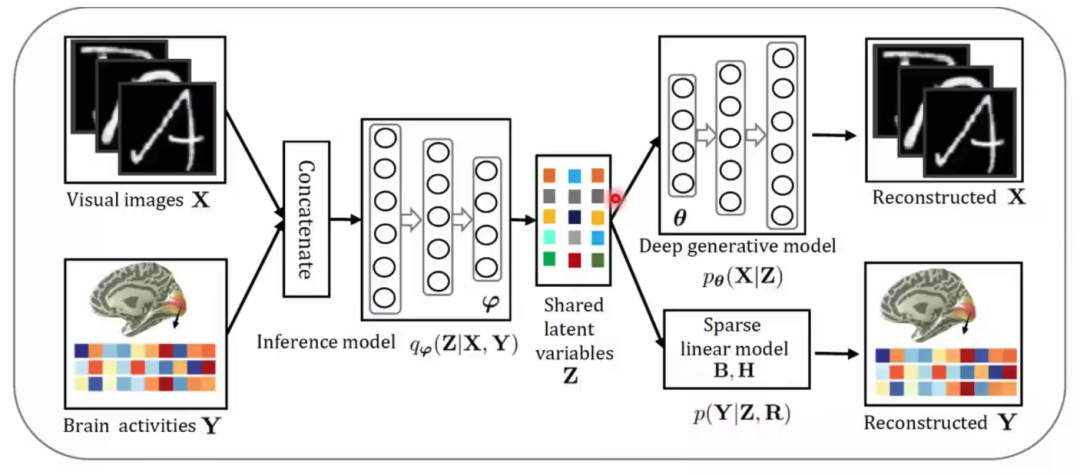
圖7 多視圖生成式自編碼模型訓練
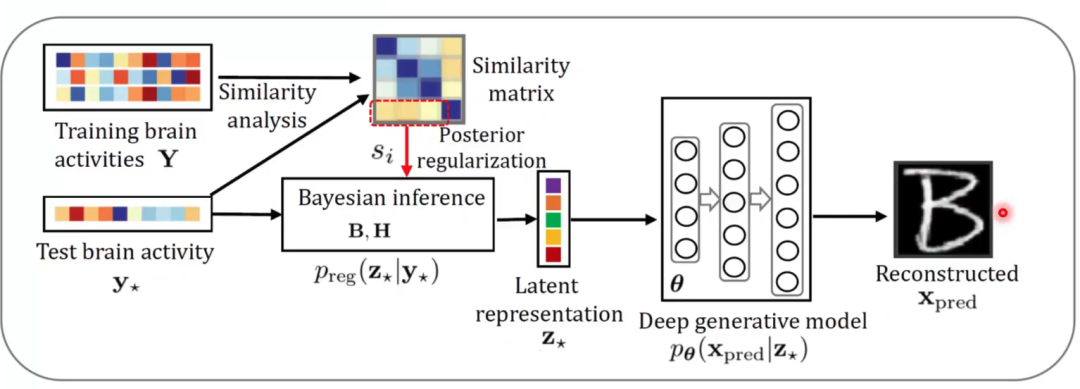
圖8 多視圖生成式自編碼模型測試
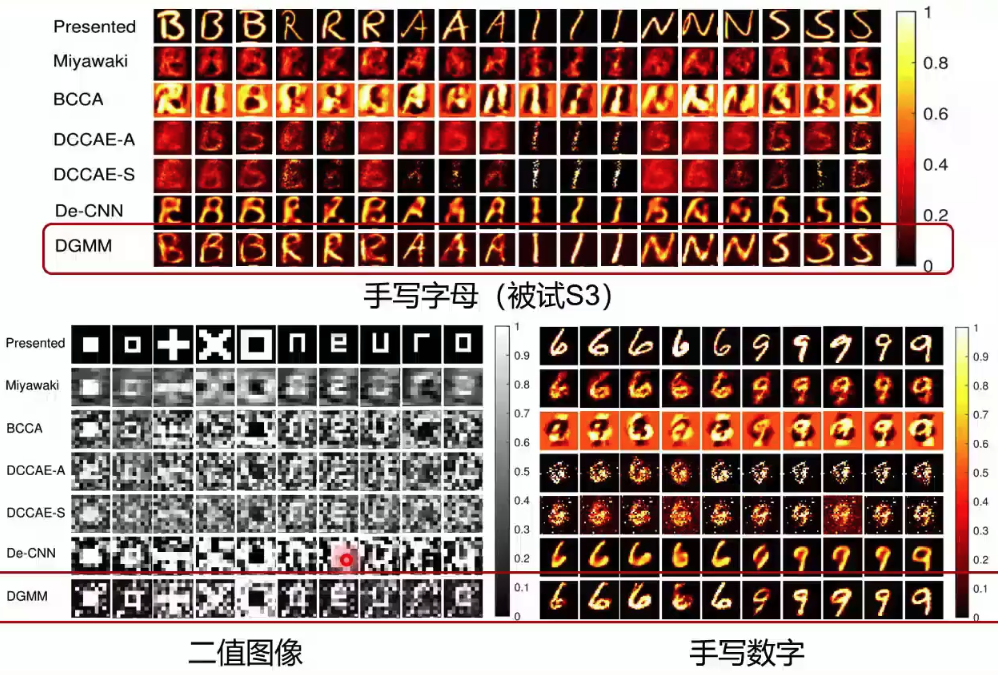
圖9 多視圖生成式自編碼模型生成效果
四、進一步工作
先前研究也存在一些不足之處,例如:
· 多用線性模型:不能學習到深層次的特征
· 單一任務
· 單一模態:只能學到單模態信息
不能利用大量非成對數據
在進一步工作中,將對這些問題進行一一改進:
· 使用深度學習:能學習到層次化的特征,表達能力強
· 多任務:能同時進行分類和重建任務
· 多模態融合:多個模態互相補充有利于解碼效果的提升
· 半監督:能對大量的非成對數據,或者對缺失模態補全
? ? ? ?隨后的研究不僅對圖像進行重建,還對其進行了分類;不僅使用了fMRI信號,還使用了EEG信號,不僅使用了成對的監督學習數據,還使用了大量非成對數據進行半監督學習。
五、多模態融合的對抗神經信息編碼
? ? ? ?在多視圖生成式自編碼模型基礎上,何老師課題組博士生李丹搭建了新的網絡,以用于基于多模態融合的對抗神經信息解碼。從圖10中,我們可以了解該網絡的框架。最上層輸入圖片到標簽的過程是一個AlexNet,該網絡可以學習圖片的分類標簽,并在fc7層輸出一組語義特征。對于文本或EEG信號這樣的非圖像信息,作者也訓練一個網絡來提取語義特征fc2和分類。當這兩個網絡的數據是成對數據的時候,在兩組語義特征間計算一個損失,使兩組特征相互聯系。對于非圖像的網絡,作者提取了語義特征和分類標簽輸入一個生成器生成圖像。生成圖片之后,將圖片輸入一個判別網絡判斷圖片是真實圖片還是生成圖片。如果是成對數據生成的圖片,還要將生成圖片和原始圖片一起輸入另一個判別網絡,以判斷兩張圖片是否對應。
? ? ? ?在測試中,我們就可以輸入非圖像信息(大腦信號或文本)提取語義特征和分類,再輸入訓練好的生成器重建圖像信息。
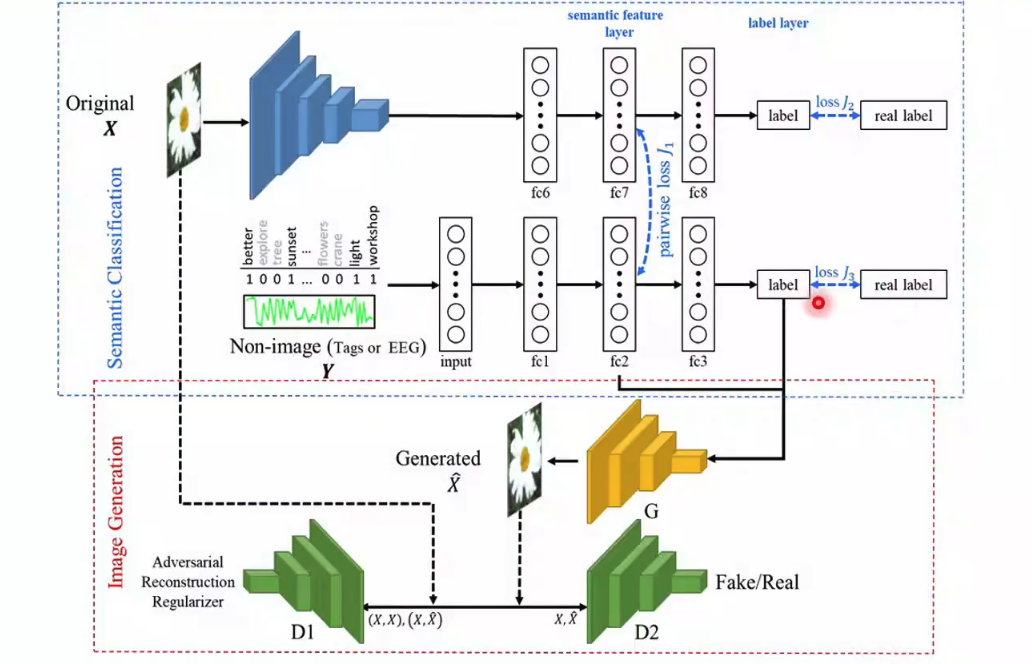
圖10 基于多模態融合的對抗神經信息解碼網絡結構
? ? ? ?在以上網絡結構的條件下,基于fMRI信號的半監督跨模態圖像生成,在實踐中取得了較多視圖生成式自編碼模型更好的效果。基于EEG信號的半監督跨模態圖像生成(圖11)中也可以看到,由于使用了GAN,生成的圖片較之前更為清晰;且由于輸入了語義信息,包含了明確的語義特征。總的來說,這個研究將大腦活動的語義學習和圖像重建任務統一在同一個框架下,使得解碼結果語義明確。同時充分利用非成對的圖像數據可以很好的輔助跨模態圖像生成任務,使圖片重建質量提升,變得更加清晰。

圖11 基于EEG信號的半監督跨模態圖像生成示例
六、其他思路
? ? ? ?接下來何老師分享了其他的一些思路。同樣是對之前模型的擴展,將多視圖生成式自編碼模型中添加了語義這一輸出,就可以得到語義信息的解碼(圖12)。由于圖像刺激的類別或者向量包含了圖像刺激中的高層次語義信息,該模型可以把大腦響應解碼到高層次的語義空間。
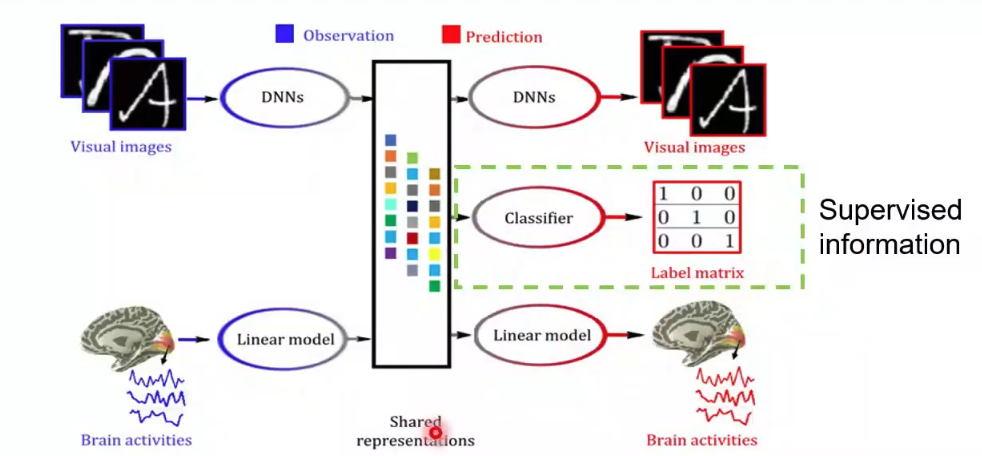
圖12 語義信息的解碼示例
? ? ? ?將不同人的大腦信號看做不同的視圖,再利用多視圖生成式自編碼模型,就可以得到多被試解碼與腦-腦通訊模型(圖13)。該模型可以綜合利用多個被試的大腦響應數據,提高模型的泛化能力。如果我們將一個人的大腦響應解碼到另一個人的大腦響應上,則該模型不僅可以實現單個被試的大腦響應解碼,還可以實現多個被試間大腦響應的相互轉換。
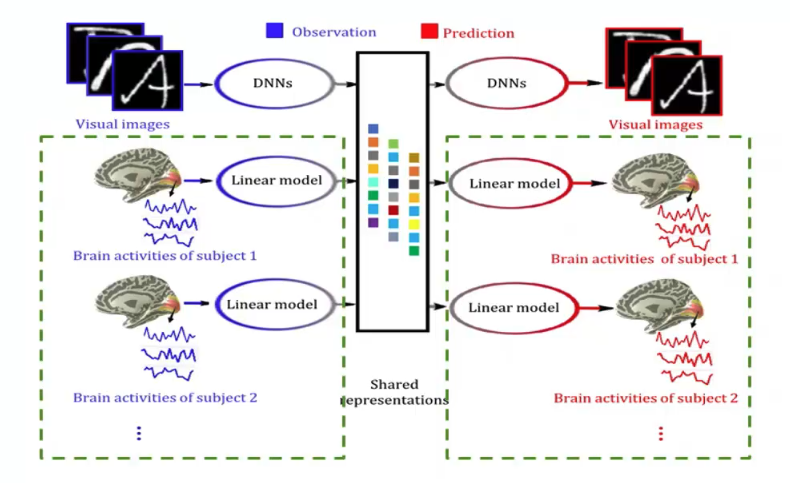
圖13 多被試解碼與腦-腦通訊模型示例
? ? ? ?類似的,多視圖生成式自編碼模型還可以應用在更加復雜的工作上,例如動態圖像(視頻)重建。如何根據大腦響應重建動態的視覺刺激場景是一個更具挑戰性的問題。將“推理網絡”和“生成網絡”的類型從多層感知機(MLPs)或卷積神經網絡(CNNs)升級為可以處理時間序列數據的遞歸神經網絡(Recurrent Neural Networks, RNNs),便可以嘗試進行動態視覺場景的重建。
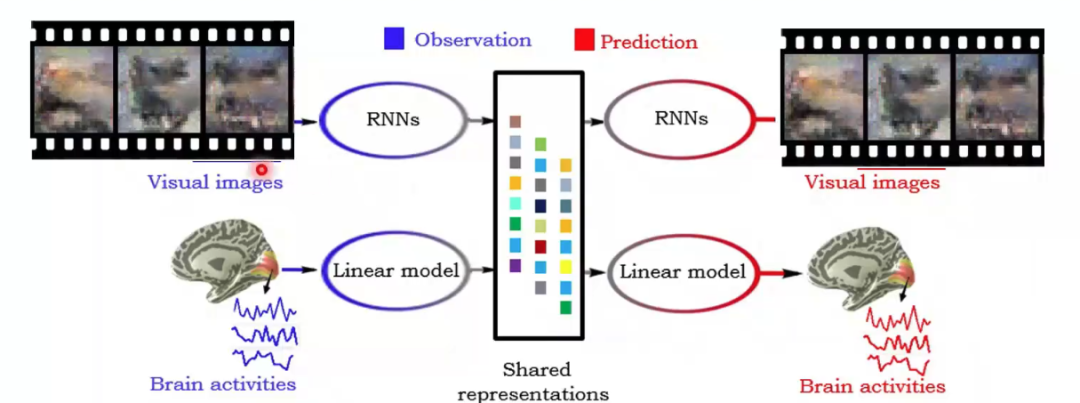
圖14 動態圖像(視頻)重建模型示例
七、總結和展望
何老師對視覺信息編解碼的工作做了如下總結和展望:
本質:建立外界視覺刺激信息與大腦響應之間的映射模型
編碼:通過研究視覺信息編碼,建立類腦計算模型
解碼:通過研究視覺信息解碼,服務于腦機接口研究
模型:提出了基于多視圖生成模型的雙向建模框架
結果:在圖像重構(信息編碼)方面性能優異
展望:
· 復雜自然場景的重構工作還在進行中
· 將采用動態編解碼,比如變分RNN,進行視頻重建
· 借鑒機器翻譯、圖像翻譯、對偶學習、自監督學習等思想
· 嘗試其他類型的深度生成模型,如GAN等
· GAN與VAE的結合
該講座介紹的研究的原文和代碼如下,歡迎感興趣的同學進一步研究:
代碼:https://github.com/ChangdeDu/DGMM
網站:http://nica.net.cn
參考文獻:
1. Mauro Manassi, Bilge Sayim, Michael H. Herzog, When crowding of crowding leads to uncrowding, Journal of Vision 2013;13(13):10. doi: https://doi.org/10.1167/13.13.10.
2. Kendrick N. Kay, Jonathan Winawer, Aviv Mezer, and Brian A. Wandell, Compressive spatial summation in human visual cortex, Journal of Neurophysiology 2013 110:2, 481-494
3. Chang de Du, Chang ying Du, Lijie Huang, Huiguang He, Reconstructing perceived images from human brain activities with Bayesian deep multiview learning, IEEE Transactions on Neural Networks and Learning Systems, 2019/8(2018/12/12),30(8), pp:2310-2323,
4. Dan Li, Changde Du, Huiguang He, Semi-supervised cross-modal image generation with generative adversarial networks, Pattern Recognition, 2020/4(2019/11/12),100,pp:107085,
5. Changde Du, Lijie Huang, Changying Du, Huiguang He. Hierarchically Structured Neural Decoding with Matrix-variate Gaussian Prior for Pereceived Image Reconstruction. AAAI 2020
本文作者:NCC lab 魏晨
校對:何暉光
廣東省深圳市南山區
學苑大道1088號
bme@sustech.edu.cn

關注微信公眾號




